Gene Model Identifier
TTHERM_00133730
Standard Name
PARS11
(PARtner of Spo11)
Aliases
PreTt24296 | 10.m00345 | 3698.m00067
Description
PARS11 Protein required for the formation and control of meiotic DNA double-strand breaks; Functionally similar to budding yeast Rec114; hypothetical protein
Genome
Browser (Macronucleus)
No Genome Browser Data Present
Genome Browser (Micronucleus)
No Genome Browser Data Present
>TTHERM_00133730(coding)
ATGCTAAGTTAAATTCTAGCTAAGATTCAACAAATTAAAATTATTAAATTATCAAAATAA
AAAACACCAAAAAGATTAAAAAAATCAGAAGTAAGAAAAAATACAAATATGAGTCTGAAA
ACATATATCAATAAGAAGAAAAGCTAAAACTTAGGTTCTTCATAGTCATCGGCTGCAGCT
CTCACATCACTTTAGTCAAATTGCTTTACAGCAAAGGGATAAATGGTTTCTTAAAATAGC
TAGAACTCACAGAATACCATTCAAATGCAGTGCAATACACAAACTCAGTAGATACTCTCA
CAAGCTTCATAATTTCCTGTGCCTAAAAACTCTAGCCTTATGATTGAAGAACCAAATATC
TTTGGATAAACTGGATACAGCTCATTCAAAAATAAGAACCTAAATTCTACTTAGAATACA
TCCTTTTTAAATTAGTTATCCTAAGACGAAGCTAATGATTCTTACAATTAAATTCTACAT
GAGAATAATTTTATTTAAAATCCTAATCTGAACTAAAGCTTTCTAAATTAAAGCTATCAA
CTTCTTTCATAGCATAACCTAAAGTAATCACAATTGTTTCTTCCAGCGATCCAAGAAAGT
AAGGTCTCTTAATTTGATGGTAAGTCTAGCTAGATATTTAATCCTTCTGAATCAAGGCTA
AATCATCCTAATCTGATATAAAGTAGCTTGATGGTTGGACAAATTTCTTAGTAATAATAA
CTTGCAAATATTTCGCTGCAGCTCTTATAAGATGAAATATTGAAATAAAAGATTGAATAA
AGAGAAAGAGAATTAATCCTAAAGCAAGAATTGCTATAAGAAATGAGAGATTTAAAACAC
TTTTTCTAGAGCAATGTAATTAAATAAATAGAAGATAAAAATGAATAAATGCAGGGTGAG
TGTTAGAAGAGCATTGAAGAAGTTTAAAAAAAGGTGGAAAATGTTGTTAAAACTATTTTT
GATTACATCAAAGATGAAAAGCAAGAGGAAAAAAAGAAAAACTCTGTAGCATAATCAGAC
TATGCATAGGATATTTCAGATTTATATAATACTGTTAATTCCATTAAAGGAAAATTAGAT
AAAGAAGGTTTAAATCAATAATTTTAACAAGATTTGAATAAAGCTATAAAGATCATATTT
AGTAAAATCAACTCTGCAAAAAGATCTGTAAAAAAACAGATTGTTCAAACAAACATGAGT
CTAAGGAATAAAAGGAAAAAGGCAACCTAAACTTAAAATAATTGA
>TTHERM_00133730(gene)
TACAACTTCAATTTTAAATTATTGATCAGAAATATCTCTATGCTAAGTTAAATTCTAGCT
AAGATTCAACAAATTAAAATTATTAAATTATCAAAATAAAAAACACCAAAAAGATTAAAA
AAATCAGAAGTAAGAAAAAATACAAATATGAGTCTGAAAACATATATCAATAAGAAGAAA
AGCTAAAACTTAGGTTCTTCATAGTCATCGGCTGCAGCTCTCACATCACTTTAGTCAAAT
TGCTTTACAGCAAAGGGATAAATGGTTTCTTAAAATAGCTAGAACTCACAGAATACCATT
CAAATGCAGTGCAATACACAAACTCAGTAGATACTCTCACAAGCTTCATAATTTCCTGTG
CCTAAAAACTCTAGCCTTATGATTGAAGAACCAAATATCTTTGGATAAACTGGATACAGC
TCATTCAAAAATAAGAACCTAAATTCTACTTAGAATACATCCTTTTTAAATTAGTTATCC
TAAGACGAAGCTAATGATTCTTACAATTAAATTCTACATGAGAATAATTTTATTTAAAAT
CCTAATCTGAACTAAAGCTTTCTAAATTAAAGCTATCAACTTCTTTCATAGCATAACCTA
AAGTAATCACAATTGTTTCTTCCAGCGATCCAAGAAAGTAAGGTCTCTTAATTTGATGGT
AAGTCTAGCTAGATATTTAATCCTTCTGAATCAAGGCTAAATCATCCTAATCTGATATAA
AGTAGCTTGATGGTTGGACAAATTTCTTAGTAATAATAACTTGCAAATATTTCGCTGCAG
CTCTTATAAGATGAAATATTGAAATAAAAGATTGAATAAAGAGAAAGAGAATTAATCCTA
AAGCAAGAATTGCTATAAGAAATGAGAGATTTAAAACACTTTTTCTAGAGCAATGTAATT
AAATAAATAGAAGATAAAAATGAATAAATGCAGGGTGAGTGTTAGAAGAGCATTGAAGAA
GTTTAAAAAAAGGTGGAAAATGTTGTTAAAACTATTTTTGATTACATCAAAGATGAAAAG
CAAGAGGAAAAAAAGAAAAACTCTGTAGCATAATCAGACTATGCATAGGATATTTCAGAT
TTATATAATACTGTTAATTCCATTAAAGGAAAATTAGATAAAGAAGGTTTAAATCAATAA
TTTTAACAAGATTTGAATAAAGCTATAAAGATCATATTTAGTAAAATCAACTCTGCAAAA
AGATCTGTAAAAAAACAGATTGTTCAAACAAACATGAGTCTAAGGAATAAAAGGAAAAAG
GCAACCTAAACTTAAAATAATTGAATTTTAATATCAATTATTTTTTAATAATATTTTTTA
GTTATATTTTTGTGGATTGTACAAATAAACTAAGAATAAATAACAAGAATAAAAATTTTT
TATTTTTTTAAAAAAACTTTATTTCTTTATTGGTTAGAAA
>TTHERM_00133730(protein)
MLSQILAKIQQIKIIKLSKQKTPKRLKKSEVRKNTNMSLKTYINKKKSQNLGSSQSSAAA
LTSLQSNCFTAKGQMVSQNSQNSQNTIQMQCNTQTQQILSQASQFPVPKNSSLMIEEPNI
FGQTGYSSFKNKNLNSTQNTSFLNQLSQDEANDSYNQILHENNFIQNPNLNQSFLNQSYQ
LLSQHNLKQSQLFLPAIQESKVSQFDGKSSQIFNPSESRLNHPNLIQSSLMVGQISQQQQ
LANISLQLLQDEILKQKIEQRERELILKQELLQEMRDLKHFFQSNVIKQIEDKNEQMQGE
CQKSIEEVQKKVENVVKTIFDYIKDEKQEEKKKNSVAQSDYAQDISDLYNTVNSIKGKLD
KEGLNQQFQQDLNKAIKIIFSKINSAKRSVKKQIVQTNMSLRNKRKKATQTQNN


 Identifiers and Description
Identifiers and Description
 External Links
External Links
 Domains
Domains
 Gene Expression Profile
Gene Expression Profile
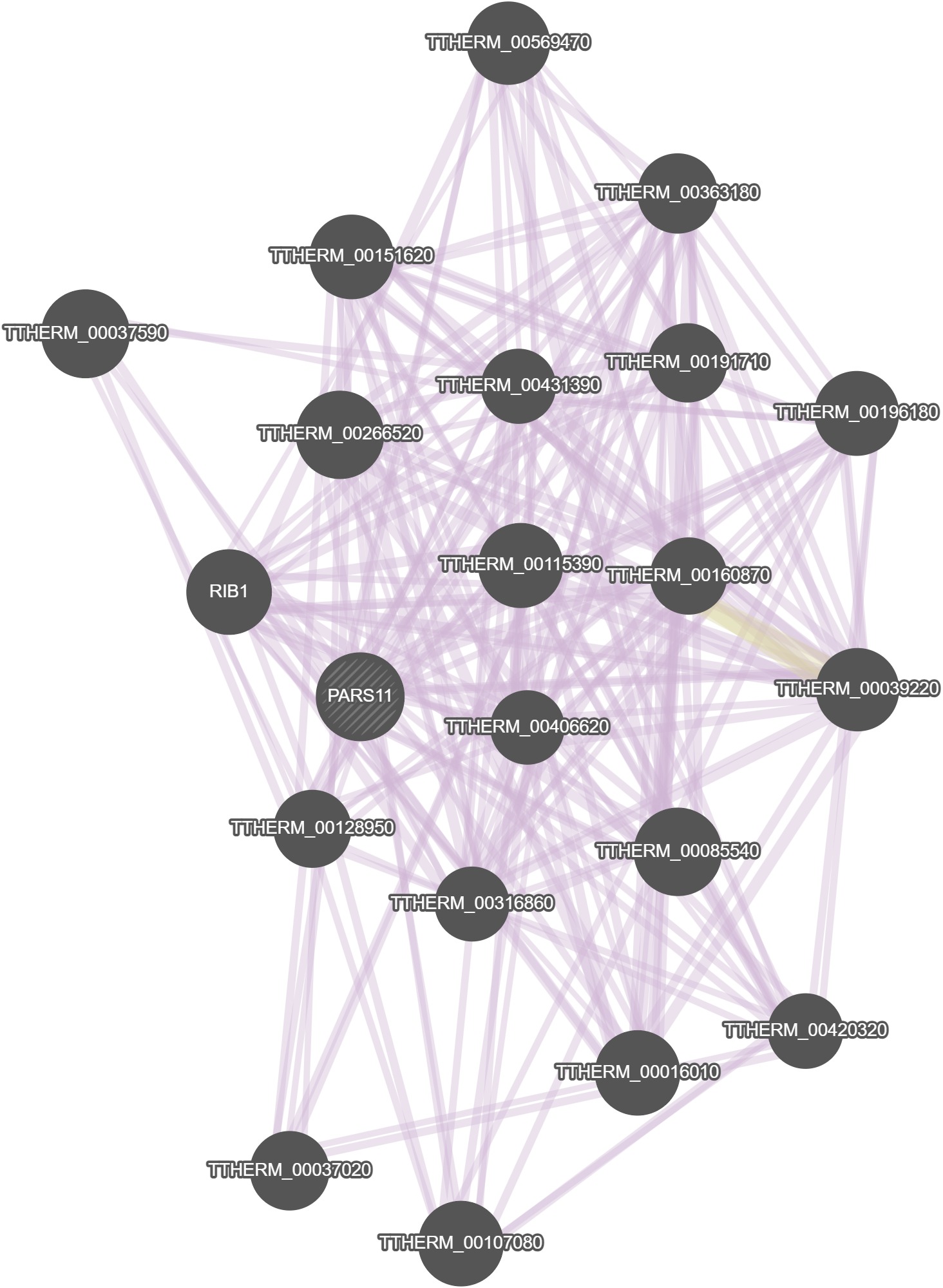
 GeneMania
GeneMania
 General Information
General Information
 Associated Literature
Associated Literature
 Sequences
Sequences
