Gene Model Identifier
TTHERM_00134970
Standard Name
CCT5
(Chaperonin Containing TCP-1 ortholog 5)
Aliases
PreTt24321 | 10.m00370 | 3698.m00091
Description
CCT5 TCP-1 (CTT or eukaryotic type II) chaperonin family epsilon subunit; Chaperone tailless complex polypeptide 1 (TCP-1)
Genome
Browser (Macronucleus)
No Genome Browser Data Present
Genome Browser (Micronucleus)
No Genome Browser Data Present
>TTHERM_00134970(coding)
ATGTCTTTAGCTTTTGACGAATACGGACGCCCCTTCATCATTATCAGAGAATAAGACTAA
AAGAAACGTCTTAAAGGTATCGATGCATACAAAGCTAACATCTAAGCTGCCAAGACTATT
GCTAGCACTTTAAGATCATCCTTGGGTCCTAAGGGTATGGATAAGATGATGATCTCTCCT
GATGGAGATGTCAGTGTTACCAATGATGGTGCTACCATTGTTGAAAAGATGGACATTTAA
CATCCTGTTGCAAAATTGATGGTTGAACTCAGTCAATCTTAAGATAATGAAATTGGTGAT
GGTACCACTGGTGTTGTTGTTTTAGCTGGTGCATTGTTGGAACAAGCCAACATCCTCATC
GATAAGGGTCTTCACCCTCTTAAGATTGCTGACGGTTTCGACAAGGCTTGTGAAATCGCT
TGCGAAAGACTTGAATAAATTGCTGAAGACATTGACATCAACGAAAATACCCACGAAAGA
TTAGTCGAAGCTGCCATGACTGCTTTGAGCTCTAAGGTCGTTAGTAAAAATAAAAGAAAG
ATGGCTTAAATCTCCGTTGATGCCGTCCTTTCCGTTGCTGATCTTGAAAGAAGAGATGTC
AACTTTGACTTGATTAAGCTCCAAGAAAAGACTGGAGGTTCCTTAGAAGATACTAGACTC
ATCCAAGGTATTTTAGTTGAAAAGGATATGTCTCATCCTTAAATGCCCAAGGAAATTTAG
GATGCTAAGATTGCCATCTTAACCTGCCCCTTCGAACCCCCTAAACCCAAAACCAAGCAT
AACATTAACATTACTAACGCTGAAGATTACAAGAAATTATACGCCTAAGAATAATAATAT
TTCAAGGATATGGTTGCTGACTGCAAAAAGTCTGGTGCCAACCTTATTATGTGCCAATGG
GGTTTCGATGATGAAGCTAATCATTTATTATTATAAGCTGATTTACCCGCTGTTAGATGG
GTTAGCGGTACTGATATTGAATTGATTGCTGTCGCCACTGGTGGTAGAATCGTACCAAGA
TTCGAAGAGCTCTCTGCTGATAAGTTAGGTGAAGCTAAGGTCGTTAGAGAAATTTAATTC
GGTACTTCCAATGAAAGAATGCTCGTTATTGAAGAATGCAAGCAATCTAAGGCTGTTACT
ATTTTGATTAGAGGTGGTTCTAACATGATTGTCTCTGAAGCCAAAAGAAGTATTCACGAT
GCTAACTGTGTTGTTAGAAACTTAATCAAGTGCCCTAAGGTCGTTTATGGTGGTGGTTCT
GCTGAAATTGCTTGTGCTTTAACTGTTAACTAAGAAGCTGATAAGATTTCATCAGTTGAA
TAATACGCTGTTAGAGCTTTCGCTGATGCTTTGGAAGATATTCCCAACGCTTTAGCTGAT
AACTCTGGTTTAAATCCTATTGAAGCTGTTGCTAATGCTAAGGCCTTATAGGTTAGTCAA
AACAATCCTAGAATTGGTGTTGACTGCTTACTTGAAGGTACATCTGATATGAAAGAATAG
AAGGTATATGAAACTTACTTATCCAAGAGATAATAATTCTAATTAGCTACTTAAGTTGTT
AAGATGATCTTAAAGATTGATGATGTTATTTCTCCTGATCACTAATGA
>TTHERM_00134970(gene)
AAAAAACAAAAAATTAAATAAATTAACAAAAACATAAACAAAAAACACATACAAAAATCA
ATAAATTTATTAAGATATGTCTTTAGCTTTTGACGAATACGGACGCCCCTTCATCATTAT
CAGAGAATAAGACTAAAAGAAACGTCTTAAAGGTATCGATGCATACAAAGCTAACATCTA
AGCTGCCAAGACTATTGCTAGCACTTTAAGATCATCCTTGGGTCCTAAGGGTATGGATAA
GATGATGATCTCTCCTGATGGAGATGTCAGTGTTACCAATGATGGTGCTACCATTGTTGA
AAAGATGGACATTTAACATCCTGTTGCAAAATTGATGGTTGAACTCAGTCAATCTTAAGA
TAATGAAATTGGTGATGGTACCACTGGTGTTGTTGTTTTAGCTGGTGCATTGTTGGAACA
AGCCAACATCCTCATCGATAAGGGTCTTCACCCTCTTAAGATTGCTGACGGTTTCGACAA
GGCTTGTGAAATCGCTTGCGAAAGACTTGAATAAATTGCTGAAGACATTGACATCAACGA
AAATACCCACGAAAGATTAGTCGAAGCTGCCATGACTGCTTTGAGCTCTAAGGTCGTTAG
TAAAAATAAAAGAAAGATGGCTTAAATCTCCGTTGATGCCGTCCTTTCCGTTGCTGATCT
TGAAAGAAGAGATGTCAACTTTGACTTGATTAAGCTCCAAGAAAAGACTGGAGGTTCCTT
AGAAGATACTAGACTCATCCAAGGTATTTTAGTTGAAAAGGATATGTCTCATCCTTAAAT
GCCCAAGGAAATTTAGGATGCTAAGATTGCCATCTTAACCTGCCCCTTCGAACCCCCTAA
ACCCAAAACCAAGCATAACATTAACATTACTAACGCTGAAGATTACAAGAAATTATACGC
CTAAGAATAATAATATTTCAAGGATATGGTTGCTGACTGCAAAAAGTCTGGTGCCAACCT
TATTATGTGCCAATGGGGTTTCGATGATGAAGCTAATCATTTATTATTATAAGCTGATTT
ACCCGCTGTTAGATGGGTTAGCGGTACTGATATTGAATTGATTGCTGTCGCCACTGGTGG
TAGAATCGTACCAAGATTCGAAGAGCTCTCTGCTGATAAGTTAGGTGAAGCTAAGGTCGT
TAGAGAAATTTAATTCGGTACTTCCAATGAAAGAATGCTCGTTATTGAAGAATGCAAGCA
ATCTAAGGCTGTTACTATTTTGATTAGAGGTGGTTCTAACATGATTGTCTCTGAAGCCAA
AAGAAGTATTCACGATGCTAACTGTGTTGTTAGAAACTTAATCAAGTGCCCTAAGGTCGT
TTATGGTGGTGGTTCTGCTGAAATTGCTTGTGCTTTAACTGTTAACTAAGAAGCTGATAA
GATTTCATCAGTTGAATAATACGCTGTTAGAGCTTTCGCTGATGCTTTGGAAGATATTCC
CAACGCTTTAGCTGATAACTCTGGTTTAAATCCTATTGAAGCTGTTGCTAATGCTAAGGC
CTTATAGGTTAGTCAAAACAATCCTAGAATTGGTGTTGACTGCTTACTTGAAGGTACATC
TGATATGAAAGAATAGAAGGTATATGAAACTTACTTATCCAAGAGATAATAATTCTAATT
AGCTACTTAAGTTGTTAAGATGATCTTAAAGATTGATGATGTTATTTCTCCTGATCACTA
ATGAAAAACATTTAATGATTGATAGAAATAAAAATTTTTCAACTTTAAAATTATAGTAAT
AATTGTAATGAATTTAACCTAAATAGATTACTGAATTAGTTGGTGTCTACAAACTTAAAA
TATATTTACAATCTTCCTAATTTGCATTAAAATATATTAAATGATTATTTCATTAATATT
AATTGAATTATCTGTTAAGCTTCATAAATTTGTAATCTTCGTATATGCATGCATCATTTC
AGATATTCAATTTTATTA
>TTHERM_00134970(protein)
MSLAFDEYGRPFIIIREQDQKKRLKGIDAYKANIQAAKTIASTLRSSLGPKGMDKMMISP
DGDVSVTNDGATIVEKMDIQHPVAKLMVELSQSQDNEIGDGTTGVVVLAGALLEQANILI
DKGLHPLKIADGFDKACEIACERLEQIAEDIDINENTHERLVEAAMTALSSKVVSKNKRK
MAQISVDAVLSVADLERRDVNFDLIKLQEKTGGSLEDTRLIQGILVEKDMSHPQMPKEIQ
DAKIAILTCPFEPPKPKTKHNINITNAEDYKKLYAQEQQYFKDMVADCKKSGANLIMCQW
GFDDEANHLLLQADLPAVRWVSGTDIELIAVATGGRIVPRFEELSADKLGEAKVVREIQF
GTSNERMLVIEECKQSKAVTILIRGGSNMIVSEAKRSIHDANCVVRNLIKCPKVVYGGGS
AEIACALTVNQEADKISSVEQYAVRAFADALEDIPNALADNSGLNPIEAVANAKALQVSQ
NNPRIGVDCLLEGTSDMKEQKVYETYLSKRQQFQLATQVVKMILKIDDVISPDHQ


 Identifiers and Description
Identifiers and Description
 External Links
External Links
 Domains
Domains
 Gene Expression Profile
Gene Expression Profile
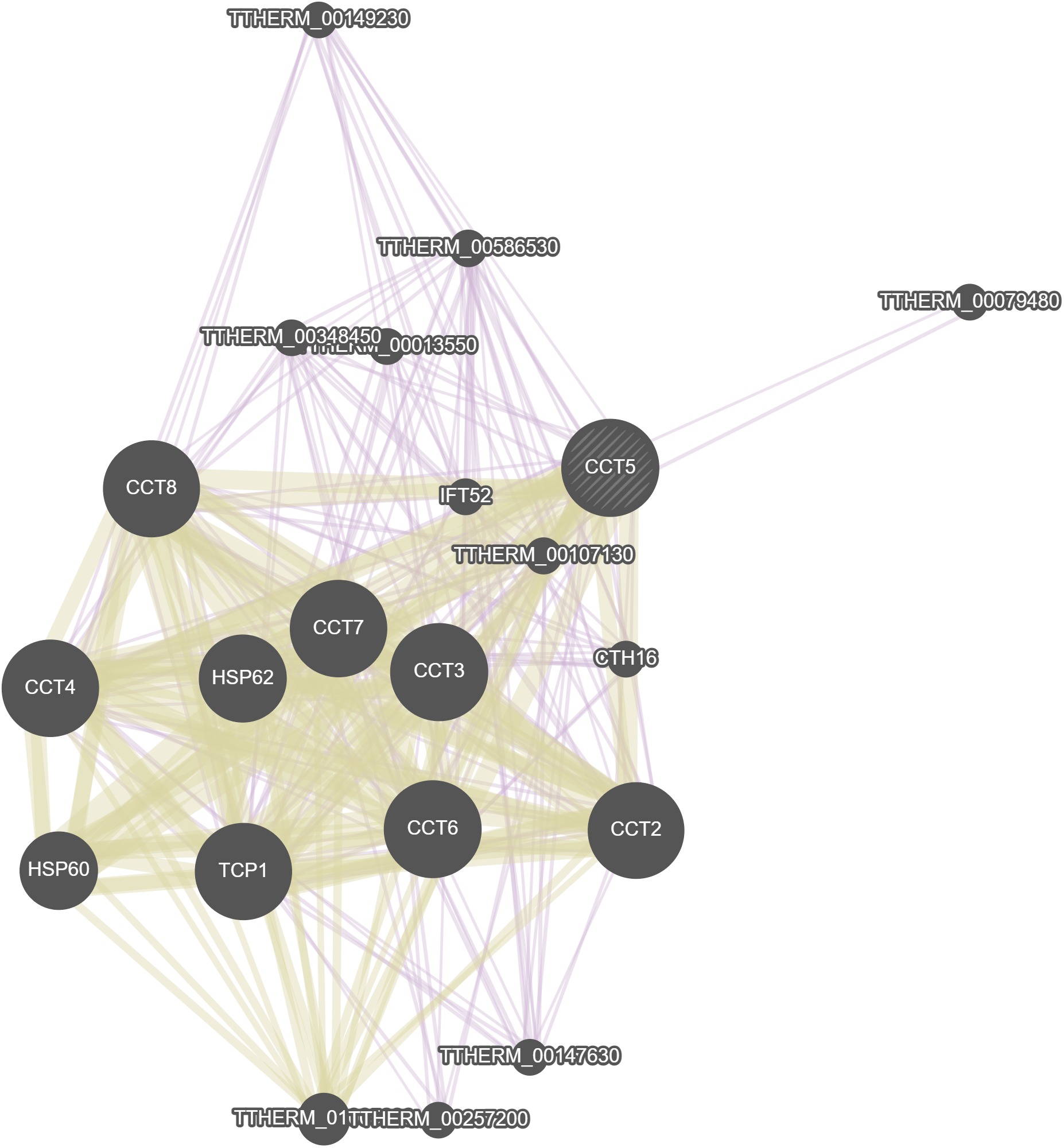
 GeneMania
GeneMania
 General Information
General Information
 Associated Literature
Associated Literature
 Sequences
Sequences
