Gene Model Identifier
TTHERM_00181100
Standard Name
PUS3
(PseudoUridine Synthase 3)
Aliases
PreTt29828 | 14.m00395 | DEG1
Description
PUS3 tRNA pseudouridine synthase; tRNA pseudouridine synthase A family protein; Pseudouridine synthase I, TruA
Genome
Browser (Macronucleus)
No Genome Browser Data Present
Genome Browser (Micronucleus)
No Genome Browser Data Present
>TTHERM_00181100(coding)
ATGGATACAATTTAATAAAGCGAATAAGGAAATATACAAATATCTTAAGAAGGCCAAAGT
GAATAGAAAGCTAACTAAGATATTAAAAAAGATGAAGAGCAAAAAAGCGAGTCATTAGAA
AGTGAAGACTTAGATAAATTTTCTAAGGAAGAAATCATTAAAAAATATTTGTTCATAAAA
AAGGAAAATTAAGTTTTAAGAAAATAATTAAACCATAACAACGACACAAAAGCCCCTATT
CCTAATAATAGCTCTTAAAATGAGACTAAAAAGTAAAAGAAAGAGCAAAAATAGAATAAC
AAAAAGGAAAGCCTATTCGAAATCTACCAATAACAGCATTATGCCTTAAAAATGTCTTAT
GTTGGAATCAATTATCAAGGCTTAGCATATTAGTAAGAAACTGACAACACTGTAGAAGAA
TAGCTCTTCAAGGCACTTGAAAAGACAACACTGATAAAAAATAGAGATAATTGCAATTTC
ACACGTTCAGGAAGAACTGACAAAGGAGTTAGTGCTTTAGGATAAGTTATTGGTATCACT
CTTAGAACTTCAATAAAAATAGGTGAAAATATTGATGAAATAGAAAATAAATTAGATTAC
ATTAAGATGCTTAATAGTAATCTTCCAGACGACATAAGGATTTTAGGTTGTTCTAAAGTT
GATCCTGCTTTTAATGCAAGATTTGATTGTTAAAAGAGAATTTATAAGTATTACTTTTTT
GAGAATTAGATGGATATTTAAAGAATGAAGGAAGCAGCTAACCTCTTTTTGGGAGAACAC
GATTTTAGAAATTTCTGCAAAATAGATGTTTTGCAAACACTTAACTATGTTAGAATTATT
TATTAACTTGATATAGAAGAAGTTTAGGCTAATTTTGGTACTCTTGACCCTCGTTCTAAA
TTATATGTAGCAACTATTCAAGGAAGTGCTTTCCTTTGGCATTAAATCAGAAACATGATG
GCTATACTTTTTCTAGTAGGCAGAAAATAAGAAGAACCTTCAATAGTTACAGAGCTTCTT
GATATTTAAAAGAATCCATCTAAACCTAATTATGAGATGGCTCCTGATTATCCTCTAGTA
TTATTTGATTGCTTGTACAATAATGTTAGTTTTAACTACAGTAGCGATTAGATAAAGATT
TATGAACATTATTTGCAGATAATCTAAAAAAAGTGTATCGAAAATTAGCTTTATATTACA
ACTCTCAATTATATGGCATAAACTGCTTAGCAATTTAACAATTATAATCTTATTTAAAAT
TCATTGATTTCAGAAGAAGCTACTCTTCGTAATAAGAAATACTAGCATCTTTCAAAAAGA
TAATGTGCTTAATCATCAGAAGACACTTTAAAAAATTTAAAAGGCAGAAAATTAGATAAG
TTTTTAATTAAGCAAGAAAAATAGATAAATTATTAATAGTAGCGCGAAGCAGAAAAGAAT
TTATCATAAACATAAGATTAAACCTCTGAAGGAAACGATACTTAAGAATGA
>TTHERM_00181100(gene)
TAAACAAAGACGAAATTTGAGTGTTGATCTCTTTATATTATTATTAAACATTCTAGTAGA
TGATTTTAGTCGATACTTTAAAAAGCTTGTGGGCTCAAATTAATAAAATTTATTAATTCT
AATTAAAAAAAGTAGTTTGATTTATAGAGAATGGATACAATTTAATAAAGCGAATAAGGA
AATATACAAATATCTTAAGAAGGCCAAAGTGAATAGAAAGCTAACTAAGATATTAAAAAA
GATGAAGAGCAAAAAAGCGAGTCATTAGAAAGTGAAGACTTAGATAAATTTTCTAAGGAA
GAAATCATTAAAAAATATTTGTTCATAAAAAAGGAAAATTAAGTTTTAAGAAAATAATTA
AACCATAACAACGACACAAAAGCCCCTATTCCTAATAATAGCTCTTAAAATGAGACTAAA
AAGTAAAAGAAAGAGCAAAAATAGAATAACAAAAAGGAAAGCCTATTCGAAATCTACCAA
TAACAGCATTATGCCTTAAAAATGTCTTATGTTGGAATCAATTATCAAGGCTTAGCATAT
TAGTAAGAAACTGACAACACTGTAGAAGAATAGCTCTTCAAGGCACTTGAAAAGACAACA
CTGATAAAAAATAGAGATAATTGCAATTTCACACGTTCAGGAAGAACTGACAAAGGAGTT
AGTGCTTTAGGATAAGTTATTGGTATCACTCTTAGAACTTCAATAAAAATAGGTGAAAAT
ATTGATGAAATAGAAAATAAATTAGATTACATTAAGATGCTTAATAGTAATCTTCCAGAC
GACATAAGGATTTTAGGTTGTTCTAAAGTTGATCCTGCTTTTAATGCAAGATTTGATTGT
TAAAAGAGAATTTATAAGTATTACTTTTTTGAGAATTAGATGGATATTTAAAGAATGAAG
GAAGCAGCTAACCTCTTTTTGGGAGAACACGATTTTAGAAATTTCTGCAAAATAGATGTT
TTGCAAACACTTAACTATGTTAGAATTATTTATTAACTTGATATAGAAGAAGTTTAGGCT
AATTTTGGTACTCTTGACCCTCGTTCTAAATTATATGTAGCAACTATTCAAGGAAGTGCT
TTCCTTTGGCATTAAATCAGAAACATGATGGCTATACTTTTTCTAGTAGGCAGAAAATAA
GAAGAACCTTCAATAGTTACAGAGCTTCTTGATATTTAAAAGAATCCATCTAAACCTAAT
TATGAGATGGCTCCTGATTATCCTCTAGTATTATTTGATTGCTTGTACAATAATGTTAGT
TTTAACTACAGTAGCGATTAGATAAAGATTTATGAACATTATTTGCAGATAATCTAAAAA
AAGTGTATCGAAAATTAGCTTTATATTACAACTCTCAATTATATGGCATAAACTGCTTAG
CAATTTAACAATTATAATCTTATTTAAAATTCATTGATTTCAGAAGAAGCTACTCTTCGT
AATAAGAAATACTAGCATCTTTCAAAAAGATAATGTGCTTAATCATCAGAAGACACTTTA
AAAAATTTAAAAGGCAGAAAATTAGATAAGTTTTTAATTAAGCAAGAAAAATAGATAAAT
TATTAATAGTAGCGCGAAGCAGAAAAGAATTTATCATAAACATAAGATTAAACCTCTGAA
GGAAACGATACTTAAGAATGAATAAAATACACAAAAATTATTTTAATCTACATAAACTAG
TTAAATTACATAAAAAAAATAAAAAAAAGATTTTAGCTTGATGTAAAATATTATATTTAT
AATTAATTAGAATGAAAATCTTAAAAATATCATTCGTTCATTATTTTAATGTTAAATTAT
AATTTATGTAAGCATAATTTACAAAAGTTTGGCTTTTTAGTATATTTATAGACTGATTTA
TGAT
>TTHERM_00181100(protein)
MDTIQQSEQGNIQISQEGQSEQKANQDIKKDEEQKSESLESEDLDKFSKEEIIKKYLFIK
KENQVLRKQLNHNNDTKAPIPNNSSQNETKKQKKEQKQNNKKESLFEIYQQQHYALKMSY
VGINYQGLAYQQETDNTVEEQLFKALEKTTLIKNRDNCNFTRSGRTDKGVSALGQVIGIT
LRTSIKIGENIDEIENKLDYIKMLNSNLPDDIRILGCSKVDPAFNARFDCQKRIYKYYFF
ENQMDIQRMKEAANLFLGEHDFRNFCKIDVLQTLNYVRIIYQLDIEEVQANFGTLDPRSK
LYVATIQGSAFLWHQIRNMMAILFLVGRKQEEPSIVTELLDIQKNPSKPNYEMAPDYPLV
LFDCLYNNVSFNYSSDQIKIYEHYLQIIQKKCIENQLYITTLNYMAQTAQQFNNYNLIQN
SLISEEATLRNKKYQHLSKRQCAQSSEDTLKNLKGRKLDKFLIKQEKQINYQQQREAEKN
LSQTQDQTSEGNDTQE


 Identifiers and Description
Identifiers and Description
 External Links
External Links
 Domains
Domains
 Gene Expression Profile
Gene Expression Profile
 GeneMania
GeneMania
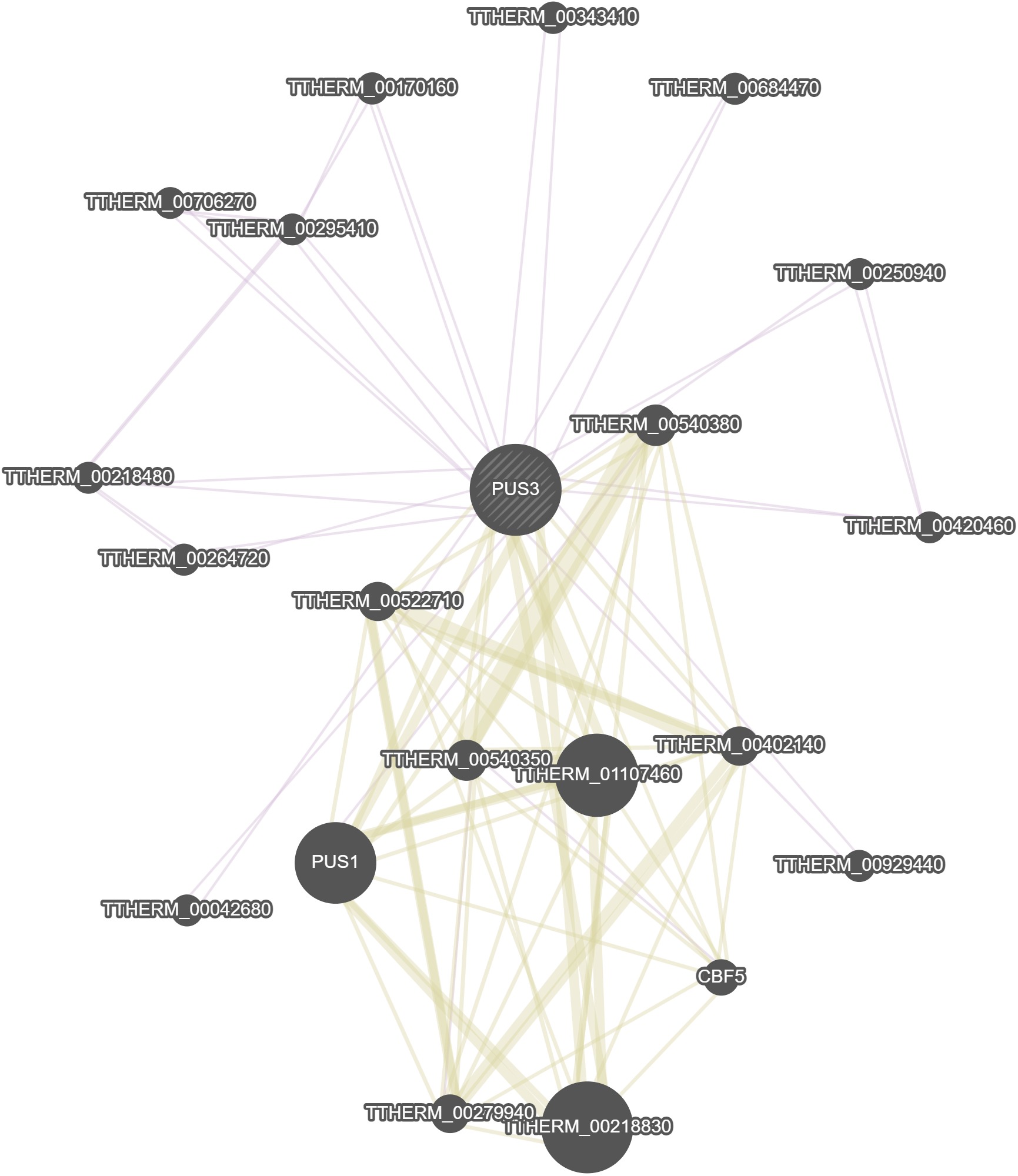
 General Information
General Information
 Associated Literature
Associated Literature
 Sequences
Sequences
