Gene Model Identifier
TTHERM_00283550
Standard Name
ERF2
(Eukaryotic Release Factor 2)
Aliases
PreTt04894 | 25.m00358 | 3694.m00141
Description
ERF2 eukaryotic peptide chain release factor subunit 1; eRF1 domain 1 family protein; Peptide chain release factor eRF1/aRF1
Genome
Browser (Macronucleus)
No Genome Browser Data Present
Genome Browser (Micronucleus)
No Genome Browser Data Present
>TTHERM_00283550(coding)
ATGATAAATTAAATAAATAAATAAATCATTAAATAAAAACTAAGTAGAAGGAAACTTTTA
CCTAAAAATACAAAATTCAAAATACCGAAAGGTCGAAATCTTAAGGATCAACAAATAATA
TTTGAATATTCTCTTAGAATTTTCAGCAAGGAAATGGAGTAGAAGCCACCGTTTTAAAAT
CCGCTTTAGAAACTGTAAGATCGAGGGACTAAAATGGATTAAAGCAGCGGCTCCTGCATG
AGCAAATAAGCTGAGGAGTAGAAGCGATTGTAAATTTCTTAATACTAATTAAGAAAACAA
TTGTAAATGCTCCGAAACATGCGAGGAGAGTAAACAAGCTGTGTTTCATTATATATTCCT
GAGAGAAAGAAATTATATGAAGTTGTCAATTATTTACAGTAAGAAGAAAGTGGTGCAGCC
TCTATTAAAAATACCCAAAATCGTAAATCTGTGCAGAGTGCTTTATCAATGCTCCGTGAA
CGTTTGAAGAATTTCAACCTTCACAAAAAGTATCCTAAAGGTATGATTTTCTTTTGTGCT
GATTCTCTAGATTCTAAGCGTCTTTTGATCGAAATTCTAGATCCTCCAAAGGCAGTTCAG
TCTTTCCGCTATTCTTGCAATACCATATTTTATCTAGATGACCTTGAATATATGCTTAAG
GACTAACCAACATATGGTTTTGTTGTCGCAGACGGACATGGATATCTGATAGCTACAGTC
TGCGGCTTTGATATTTAAATCCTCTAAAGTAAATAAGAGGATCTTCCTAATAAACATAAC
AAAGGTGGTTAGTCGTCTTTAAGATTTTCTAGGCTTTGCGATGCTGCGAGAGAAAGATTA
GTTAAGAATATAGCTGACGCTATGAGAAGATGCTATGCTAATGAGAATGGAACATAAACT
AATCTTAGTGGAATAGTGCTTTGTGGAATGAGTGATATCAAAGATAAAGTGCAAAAAGAG
CTTTAGCAGTTATGTCCTTGCATAGAGAACAAAATAGTTGCTAGCTATGATGTAAGTTAT
AGTGGTTAAGCAGGACTAAAGTAGGCTCTTTAAATGAGTACCGAGATGTTAAAGTTAGAC
TAACTCTTTTAAGAGATGAATCTCCTCAGTGACTTTTTCGCTAATTTCAGTCTTGAAACA
AGCAAAGTTGTTTATGGAGGAGAGCTAACTGTTCGAGCTTTAGAAGAAGGAAATGTTAAA
AAGCTAATTCTCTGCTAGGATTCAGAACTTCAAAGAGTTACAGTTTATAACTCTAAAACT
CAAGAAGAAACTATCTAATACTTAATGCCATCACAAGTGAAAGCACTCTAAGACTCTATT
TCAAAGACTAGTGACTAAGAAGCCAACAATAAGAAAAACTAATTACAAGTATACTCACAA
TAAAACATCAACGAATGGATTGTTGAAAATATTTCTTCATTTAGTTAAGATTTAGAAATT
GTTTTTGTAAGTGATAAGACTTAGTAAGGCGTTTAGTTTTCTAAAAGCTTTTAAGGAGTT
GGTGCTTATCTCAAATACTCTCTTGATTACTCATCACTTCATGCTCAAGAAAAAGAGAAT
GACCAACTTGAACAAGAATATTGCTATGATGACGAGGAAGGTTTTATTTGA
>TTHERM_00283550(gene)
AGTCAAAGAATTATGATAAATTAAATAAATAAATAAATCATTAAATAAAAACTAAGTAGA
AGGAAACTTTTACCTAAAAATACAAAATTCAAAATACCGAAAGGTCGAAATCTTAAGGAT
CAACAAATAATATTTGAATATTCTCTTAGAATTTTCAGCAAGGAAATGGAGTAGAAGCCA
CCGTTTTAAAATCCGCTTTAGAAACTGTAAGATCGAGGGACTAAAATGGATTAAAGCAGC
GGCTCCTGCATGAGCAAATAAGCTGAGGAGTAGAAGCGATTGTAAATTTCTTAATACTAA
TTAAGAAAACAATTGTAAATGCTCCGAAACATGCGAGGAGAGTAAACAAGCTGTGTTTCA
TTATATATTCCTGAGAGAAAGAAATTATATGAAGTTGTCAATTATTTACAGTAAGAAGAA
AGTGGTGCAGCCTCTATTAAAAATACCCAAAATCGTAAATCTGTGCAGAGTGCTTTATCA
ATGCTCCGTGAACGTTTGAAGAATTTCAACCTTCACAAAAAGTATCCTAAAGGTATGATT
TTCTTTTGTGCTGATTCTCTAGATTCTAAGCGTCTTTTGATCGAAATTCTAGATCCTCCA
AAGGCAGTTCAGTCTTTCCGCTATTCTTGCAATACCATATTTTATCTAGATGACCTTGAA
TATATGCTTAAGGACTAACCAACATATGGTTTTGTTGTCGCAGACGGACATGGATATCTG
ATAGCTACAGTCTGCGGCTTTGATATTTAAATCCTCTAAAGTAAATAAGAGGATCTTCCT
AATAAACATAACAAAGGTGGTTAGTCGTCTTTAAGATTTTCTAGGCTTTGCGATGCTGCG
AGAGAAAGATTAGTTAAGAATATAGCTGACGCTATGAGAAGATGCTATGCTAATGAGAAT
GGAACATAAACTAATCTTAGTGGAATAGTGCTTTGTGGAATGAGTGATATCAAAGATAAA
GTGCAAAAAGAGCTTTAGCAGTTATGTCCTTGCATAGAGAACAAAATAGTTGCTAGCTAT
GATGTAAGTTATAGTGGTTAAGCAGGACTAAAGTAGGCTCTTTAAATGAGTACCGAGATG
TTAAAGTTAGACTAACTCTTTTAAGAGATGAATCTCCTCAGTGACTTTTTCGCTAATTTC
AGTCTTGAAACAAGCAAAGTTGTTTATGGAGGAGAGCTAACTGTTCGAGCTTTAGAAGAA
GGAAATGTTAAAAAGCTAATTCTCTGCTAGGATTCAGAACTTCAAAGAGTTACAGTTTAT
AACTCTAAAACTCAAGAAGAAACTATCTAATACTTAATGCCATCACAAGTGAAAGCACTC
TAAGACTCTATTTCAAAGACTAGTGACTAAGAAGCCAACAATAAGAAAAACTAATTACAA
GTATACTCACAATAAAACATCAACGAATGGATTGTTGAAAATATTTCTTCATTTAGTTAA
GATTTAGAAATTGTTTTTGTAAGTGATAAGACTTAGTAAGGCGTTTAGTTTTCTAAAAGC
TTTTAAGGAGTTGGTGCTTATCTCAAATACTCTCTTGATTACTCATCACTTCATGCTCAA
GAAAAAGAGAATGACCAACTTGAACAAGAATATTGCTATGATGACGAGGAAGGTTTTATT
TGAAGAGTTTTGACTCTATTTCTTCTAAAAAATAATCTTTAAATATCAAAAAAGATTATC
TCTGAAAATAATTGCTATTATATAAAAAATAATAACTTCATTAAATTTATATCTCTCTTT
AATATATAACGTTACCAGTAAGTATATATTTGTTGAACAATTT
>TTHERM_00283550(protein)
MINQINKQIIKQKLSRRKLLPKNTKFKIPKGRNLKDQQIIFEYSLRIFSKEMEQKPPFQN
PLQKLQDRGTKMDQSSGSCMSKQAEEQKRLQISQYQLRKQLQMLRNMRGEQTSCVSLYIP
ERKKLYEVVNYLQQEESGAASIKNTQNRKSVQSALSMLRERLKNFNLHKKYPKGMIFFCA
DSLDSKRLLIEILDPPKAVQSFRYSCNTIFYLDDLEYMLKDQPTYGFVVADGHGYLIATV
CGFDIQILQSKQEDLPNKHNKGGQSSLRFSRLCDAARERLVKNIADAMRRCYANENGTQT
NLSGIVLCGMSDIKDKVQKELQQLCPCIENKIVASYDVSYSGQAGLKQALQMSTEMLKLD
QLFQEMNLLSDFFANFSLETSKVVYGGELTVRALEEGNVKKLILCQDSELQRVTVYNSKT
QEETIQYLMPSQVKALQDSISKTSDQEANNKKNQLQVYSQQNINEWIVENISSFSQDLEI
VFVSDKTQQGVQFSKSFQGVGAYLKYSLDYSSLHAQEKENDQLEQEYCYDDEEGFI


 Identifiers and Description
Identifiers and Description
 External Links
External Links
 Domains
Domains
 Gene Expression Profile
Gene Expression Profile
 GeneMania
GeneMania
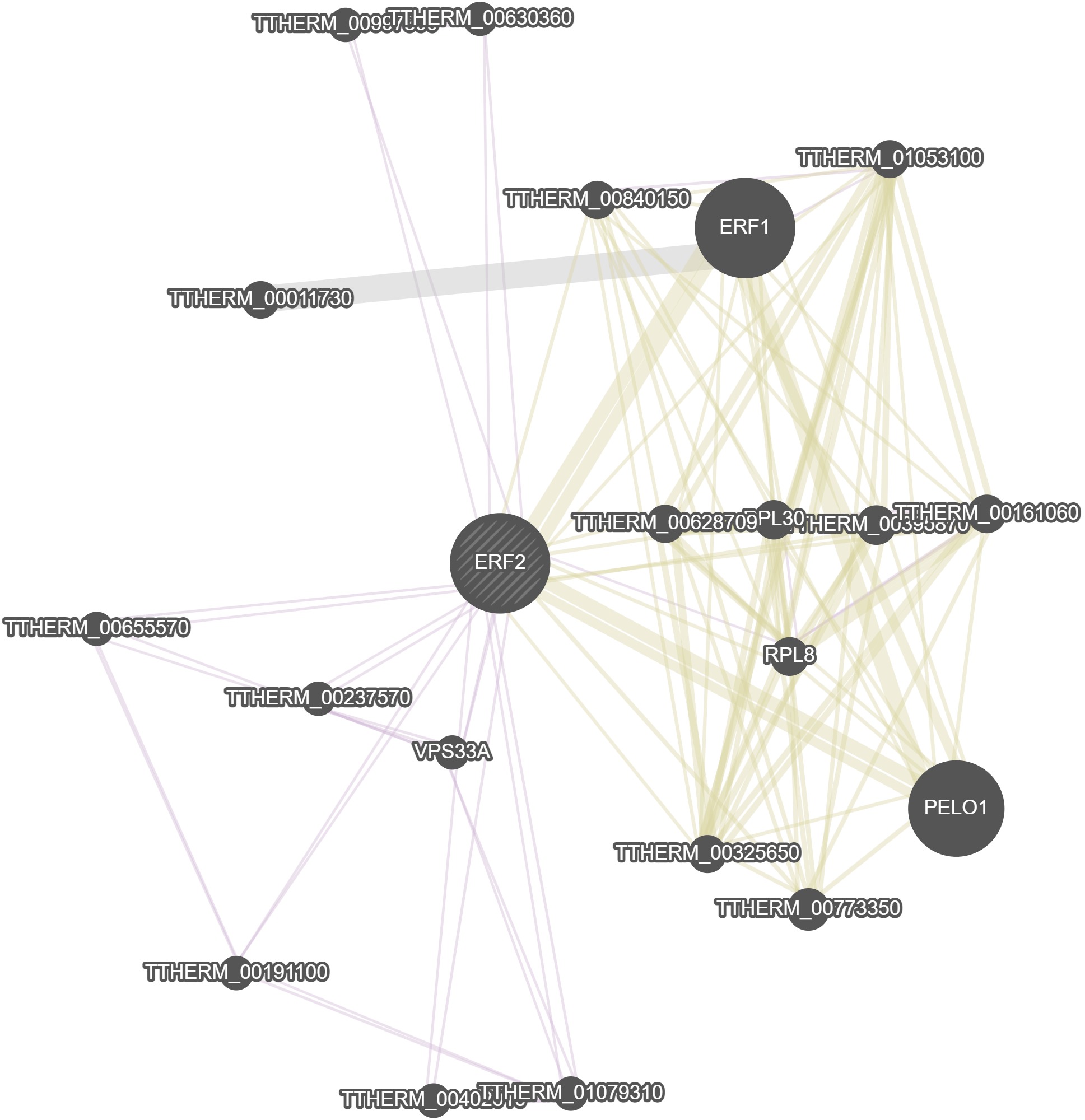
 General Information
General Information
 Associated Literature
Associated Literature
 Sequences
Sequences
