Gene Model Identifier
TTHERM_00475140
Standard Name
PDI1
(Protein Disulfide-Isomerase)
Aliases
PreTt02313 | 57.m00252 | 3709.m00112
Description
PDI1 protein disulfide-isomerase; protein disulfide-isomerase domain containing protein; Thioredoxin domain
Genome
Browser (Macronucleus)
No Genome Browser Data Present
Genome Browser (Micronucleus)
No Genome Browser Data Present
>TTHERM_00475140(coding)
ATGAACAAGACTTTGCTTTTGTTAACTATTTTGGCTGTCGGTGCTTTGGCTTCCACTGCC
CCTGCTGTCGAAGAAGGTGTCTATGTCTTAACTGACTCCAACTTCAACGAATTCATTGCC
TCCAAGCCTTTTGTTTTGGTTGAATTCTACGCCCCTTGGTGTGGTCACTGCAAGAAGCTC
GCCCCCGAATATGCTAAGGCTGCTTAAGCTTTAGCCAGTGAAAACTCCTAAGCTGTTCTC
GCTAAGGTTGATGCCACTGAATAAAAGGACCTCGGTACTAGATTCTCCATCCAAGGTTTC
CCTACCTTGAAGTTCTTCATCAACGGTTCCACTGAAAACCCTGTTGACTTCAATGGTGGT
AGAACTGAAAAGGACATCCTTAACTGGATCAAGAAGAGAACCGGTTCCGTTTCTGAAGCT
CTTAACACTGCTGAAGAATTAACCGCCTTCACTCAAAAGAACCAAGTCGCCATCGTTTAT
TTCGGTGAAAGTGAAAAGGATGCCAACTACGAAGCCTTCAAGTCTTTGGCTATGTCTTAT
GATGACCTCGCCTTCGCTCACGTTTTCAACGCTGACTTGAGAACTGCTTAAAACGCTGCT
GCTCACAACCTCGTCCTCTACAAGCACTTCGATGAAAAGAGAAACGACTTCACTGGTACC
TTCAACGTTGCTAACTTAAAGACTTTCGTTGACACCAACTCTTTCCCCATCGTTATGCCC
TTCAACGACAGAGCCATCCAAAAGGTCTTCTAACAAGGTAACCCCACTTTGTTCCTTTTC
TCCAACAGCAACGAAGCTTCCCTTGCTGCTGAAAAGGCTTTCGCTGCTTCTGCTGAAGAA
AACAGAGGTAAGATCGTCTTCTCTATCTCCAAGCCTGATGACACCTTCGGTCACTACTAA
AAACTCGCTGACTACATCGGTGTTAACACTGCTTAAGTCCCCGCTTTAATGCTCGTTCAC
TCCAGCCACGAAGTTCTTAAGTACAAGTTCACTGCTTCTGAAATCACCCATGCCACCATT
AACTAATTCGTTAGTGACTACCTTGCTGGTAAGCTCTCAACTTACTTGAAGTCTGAAGAT
ATCCCTGCCACCAACGACGAACCCGTCAAGGTCCTCGTCGGCAAGAGTTTCGATGACCTC
GTCATTAACAGCAACAAGGATGTCTTAGTTGAATTCTACGCTCCCTGGTGCGGTCACTGC
AAGCAACTTGCTCCCATCTATGATGCCGTTGCCAAGAAGCTCTCCCACAACCACAACATC
GTCATCGCTAAGATCGATTCCACCGCTAACGAAGTTCCCGGAGTCAATATTAGAGGTTTC
CCCACCATTAAGTTCTATCAAAACGGTAAGAAATCTACTCCTCTTGATTTCGAAGGTGAC
AGAACTGAAGAAGGTATCCTCAAGTACCTCAAGGAAAAGACCACCTTCCCTTGGGTTGAA
AAGAACGAAGATCTCTGA
>TTHERM_00475140(gene)
AACACCTTTTAAAAACAATAAAAAATAATGGAAATAAATGTTTGTTTTTCAAATTTTAGA
TGTTTGATGGAAATCTTATGGAATCATGGAGAAAAATTATTAAAATTTCAAGCAAAATCA
AATCTGGGTGGGGAAAACGAACTAATTATTGAAAGCCAATACACTTAAGAGTTAAGAAAG
GGGATAGGGATTTTTTTGATATAAAAGCACGTATCTAAGTCAGAAAATATCTTTTAAAAT
AATAAATAAAAATTGAAAAAATATCATTAAGAAAAAACCAAAAAAAATGAACAAGACTTT
GCTTTTGTTAACTATTTTGGCTGTCGGTGCTTTGGCTTCCACTGCCCCTGCTGTCGAAGA
AGGTGTCTATGTCTTAACTGACTCCAACTTCAACGAATTCATTGCCTCCAAGCCTTTTGT
TTTGGTTGAATTCTACGCCCCTTGGTGTGGTCACTGCAAGAAGCTCGCCCCCGAATATGC
TAAGGCTGCTTAAGCTTTAGCCAGTGAAAACTCCTAAGCTGTTCTCGCTAAGGTTGATGC
CACTGAATAAAAGGACCTCGGTACTAGATTCTCCATCCAAGGTTTCCCTACCTTGAAGTT
CTTCATCAACGGTTCCACTGAAAACCCTGTTGACTTCAATGGTGGTAGAACTGAAAAGGA
CATCCTTAACTGGATCAAGAAGAGAACCGGTTCCGTTTCTGAAGCTCTTAACACTGCTGA
AGAATTAACCGCCTTCACTCAAAAGAACCAAGTCGCCATCGTTTATTTCGGTGAAAGTGA
AAAGGATGCCAACTACGAAGCCTTCAAGTCTTTGGCTATGTCTTATGATGACCTCGCCTT
CGCTCACGTTTTCAACGCTGACTTGAGAACTGCTTAAAACGCTGCTGCTCACAACCTCGT
CCTCTACAAGCACTTCGATGAAAAGAGAAACGACTTCACTGGTACCTTCAACGTTGCTAA
CTTAAAGACTTTCGTTGACACCAACTCTTTCCCCATCGTTATGCCCTTCAACGACAGAGC
CATCCAAAAGGTCTTCTAACAAGGTAACCCCACTTTGTTCCTTTTCTCCAACAGCAACGA
AGCTTCCCTTGCTGCTGAAAAGGCTTTCGCTGCTTCTGCTGAAGAAAACAGAGGTAAGAT
CGTCTTCTCTATCTCCAAGCCTGATGACACCTTCGGTCACTACTAAAAACTCGCTGACTA
CATCGGTGTTAACACTGCTTAAGTCCCCGCTTTAATGCTCGTTCACTCCAGCCACGAAGT
TCTTAAGTACAAGTTCACTGCTTCTGAAATCACCCATGCCACCATTAACTAATTCGTTAG
TGACTACCTTGCTGGTAAGCTCTCAACTTACTTGAAGTCTGAAGATATCCCTGCCACCAA
CGACGAACCCGTCAAGGTCCTCGTCGGCAAGAGTTTCGATGACCTCGTCATTAACAGCAA
CAAGGATGTCTTAGTTGAATTCTACGCTCCCTGGTGCGGTCACTGCAAGCAACTTGCTCC
CATCTATGATGCCGTTGCCAAGAAGCTCTCCCACAACCACAACATCGTCATCGCTAAGAT
CGATTCCACCGCTAACGAAGTTCCCGGAGTCAATATTAGAGGTTTCCCCACCATTAAGTT
CTATCAAAACGGTAAGAAATCTACTCCTCTTGATTTCGAAGGTGACAGAACTGAAGAAGG
TATCCTCAAGTACCTCAAGGAAAAGACCACCTTCCCTTGGGTTGAAAAGAACGAAGATCT
CTGATCAATTTGACAATTTTAATAATAGATATTATTAGTAATAATAATATCTCACTGTTA
TTGTATTTTCTTTGTTAACTTAATATTTGTATTCTAATCCAAATATTGCTCCAATTCACA
ATCAATT
>TTHERM_00475140(protein)
MNKTLLLLTILAVGALASTAPAVEEGVYVLTDSNFNEFIASKPFVLVEFYAPWCGHCKKL
APEYAKAAQALASENSQAVLAKVDATEQKDLGTRFSIQGFPTLKFFINGSTENPVDFNGG
RTEKDILNWIKKRTGSVSEALNTAEELTAFTQKNQVAIVYFGESEKDANYEAFKSLAMSY
DDLAFAHVFNADLRTAQNAAAHNLVLYKHFDEKRNDFTGTFNVANLKTFVDTNSFPIVMP
FNDRAIQKVFQQGNPTLFLFSNSNEASLAAEKAFAASAEENRGKIVFSISKPDDTFGHYQ
KLADYIGVNTAQVPALMLVHSSHEVLKYKFTASEITHATINQFVSDYLAGKLSTYLKSED
IPATNDEPVKVLVGKSFDDLVINSNKDVLVEFYAPWCGHCKQLAPIYDAVAKKLSHNHNI
VIAKIDSTANEVPGVNIRGFPTIKFYQNGKKSTPLDFEGDRTEEGILKYLKEKTTFPWVE
KNEDL


 Identifiers and Description
Identifiers and Description
 External Links
External Links
 Domains
Domains
 Gene Expression Profile
Gene Expression Profile
 GeneMania
GeneMania
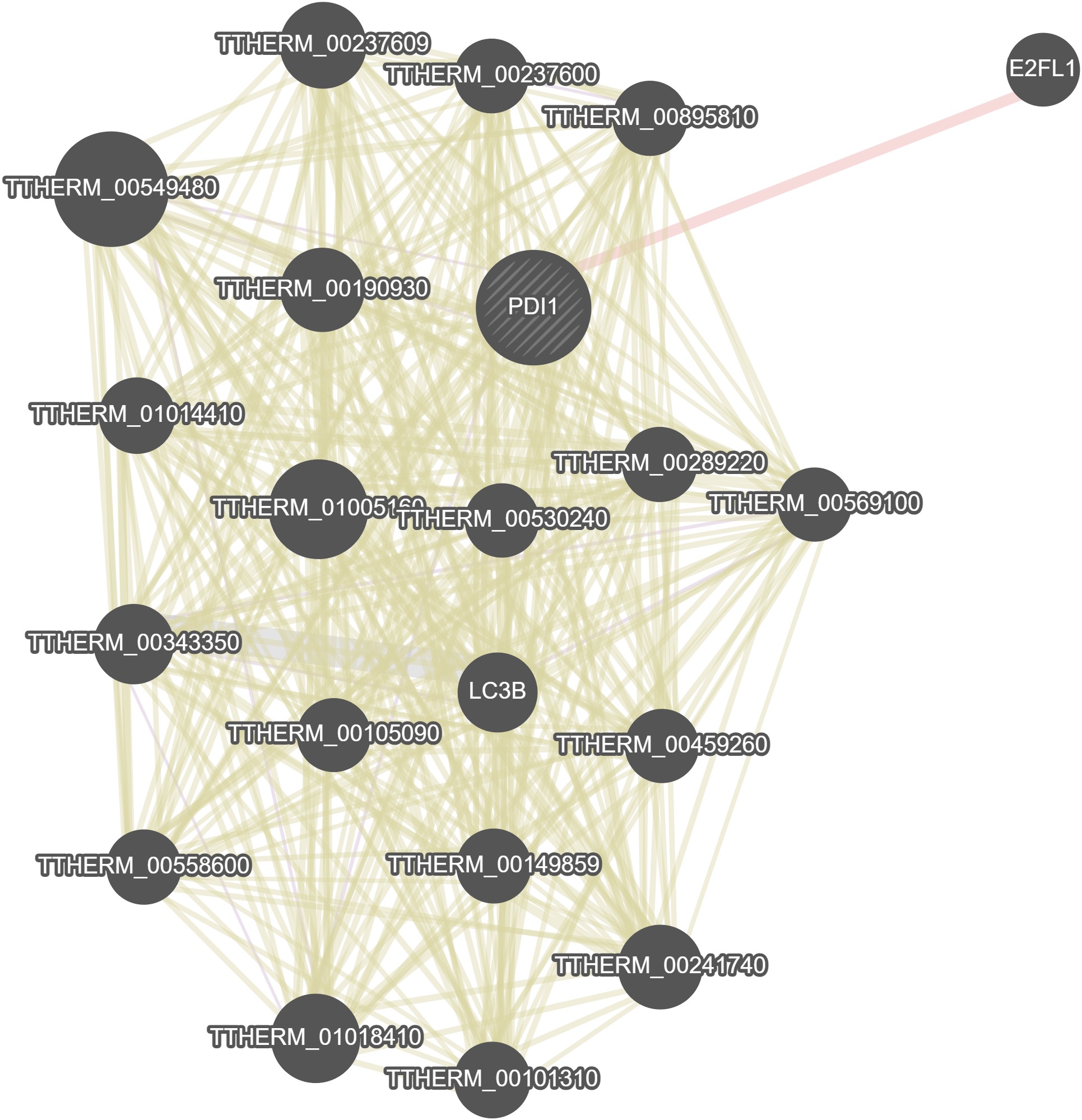
 General Information
General Information
 Associated Literature
Associated Literature
 Sequences
Sequences
