Gene Model Identifier
TTHERM_00941400
Standard Name
DISA1
(DISorientation of basal bodies)
Aliases
PreTt25146 | 171.m00055 | KDFA1 | KDF2
Description
DISA1 KDFA1 IQ calmodulin-binding motif protein; SF-assemblin domain protein; kinetodesmal fiber protein; Giardin subunit beta-like
Genome
Browser (Macronucleus)
No Genome Browser Data Present
Genome Browser (Micronucleus)
No Genome Browser Data Present
>TTHERM_00941400(coding)
ATGTCTGCTTTCGGCTCTCCTTTCCAATCTACTATTCACGGTCAATAAGAAGATTCACCC
AACAGAGTTAGAATAAAACTTCTTGGTGAAAAGTGGTAAAACATCTAACACAACATCGAC
CGTGAAAAACAAGATCGTAGAGATATTCTTGAAGAAAAGCTTAGAAATGTCGAAGATAAA
ATTAATTCTGAACGTCCTAATGACGAACAAAGATTTAAAGTATTAAAGGAGCAAGTTTTG
AAGCTTTAAAATACTCTTGAAGAAGAAAAGAATGGCAGAGAAGTTTTTGATGAAAGAAAG
GGTAAAGAAATTAAGATTCTTGATGAAAATTTACACAATCTTTTGGAAGAAGAAAAATCG
AGCAAAAGAATGGTTGAAAGCAACCTTTTGAAGCAAATCGATGAAAAGTTCTACAATATG
AACTTAAGTCTTTCCAAGAATAACAAGGCTTATGAAGAAAACACTGAAATTAAGCTTAAG
GAAGTTTAAGCCTAGATTGGATTTATTAAGGAACAAATCGATTTAGAAAAGAGAAAGAGA
GAAGAATCTACCAATGGTTTGACTGATGAGATCGAAAATGAATTGAATAAATTCCACGAT
GTCCTTCTTATTGAAAAGAAGGTTCGTGAAGAAACCCAAGCTAAAATATATAGAATGATT
GAAGATATCCACTCTAAGCTCCAAACTGAATTGGTCTAAGAAAAGAGAGACAGAGAATCC
ACAACTGAGTCTTTAATTAAACTCTTGGAAGACACTTGCTAGAGAATTGATAAGAACTTC
CGTCAATGA
>TTHERM_00941400(gene)
AATAAGGCAATCAAATAAAAAATTCATAAATAACAAAATCTTTCATTCATATAATTAAAA
GTAATATAAAAATATTAAAATAAGAAATGTCTGCTTTCGGCTCTCCTTTCCAATCTACTA
TTCACGGTCAATAAGAAGATTCACCCAACAGAGTTAGAATAAAACTTCTTGGTGAAAAGT
GGTAAAACATCTAACACAACATCGACCGTGAAAAACAAGATCGTAGAGATATTCTTGAAG
AAAAGCTTAGAAATGTCGAAGATAAAATTAATTCTGAACGTCCTAATGACGAACAAAGAT
TTAAAGTATTAAAGGAGCAAGTTTTGAAGCTTTAAAATACTCTTGAAGAAGAAAAGAATG
GCAGAGAAGTTTTTGATGAAAGAAAGGGTAAAGAAATTAAGATTCTTGATGAAAATTTAC
ACAATCTTTTGGAAGAAGAAAAATCGAGCAAAAGAATGGTTGAAAGCAACCTTTTGAAGC
AAATCGATGAAAAGTTCTACAATATGAACTTAAGTCTTTCCAAGAATAACAAGGCTTATG
AAGAAAACACTGAAATTAAGCTTAAGGAAGTTTAAGCCTAGATTGGATTTATTAAGGAAC
AAATCGATTTAGAAAAGAGAAAGAGAGAAGAATCTACCAATGGTTTGACTGATGAGATCG
AAAATGAATTGAATAAATTCCACGATGTCCTTCTTATTGAAAAGAAGGTTCGTGAAGAAA
CCCAAGCTAAAATATATAGAATGATTGAAGATATCCACTCTAAGCTCCAAACTGAATTGG
TCTAAGAAAAGAGAGACAGAGAATCCACAACTGAGTCTTTAATTAAACTCTTGGAAGACA
CTTGCTAGAGAATTGATAAGAACTTCCGTCAATGAAGATTCATATTTTGAACAATCAAAT
AAAATAAGAAAAAAGAGTTGTTTTAATAATAGTTTGAATATGATTTAAAAATTGCAACTA
TCTAAACTATATACTATATTAAATTCTATAAGACATATCTATATGTATGTTTATTTTTCT
CTATTAGTATGTTATTCTATTTCATTTCTTCTAGATTTTGACTCTCC
>TTHERM_00941400(protein)
MSAFGSPFQSTIHGQQEDSPNRVRIKLLGEKWQNIQHNIDREKQDRRDILEEKLRNVEDK
INSERPNDEQRFKVLKEQVLKLQNTLEEEKNGREVFDERKGKEIKILDENLHNLLEEEKS
SKRMVESNLLKQIDEKFYNMNLSLSKNNKAYEENTEIKLKEVQAQIGFIKEQIDLEKRKR
EESTNGLTDEIENELNKFHDVLLIEKKVREETQAKIYRMIEDIHSKLQTELVQEKRDRES
TTESLIKLLEDTCQRIDKNFRQ


 Identifiers and Description
Identifiers and Description
 External Links
External Links
 Domains
Domains
 Gene Expression Profile
Gene Expression Profile
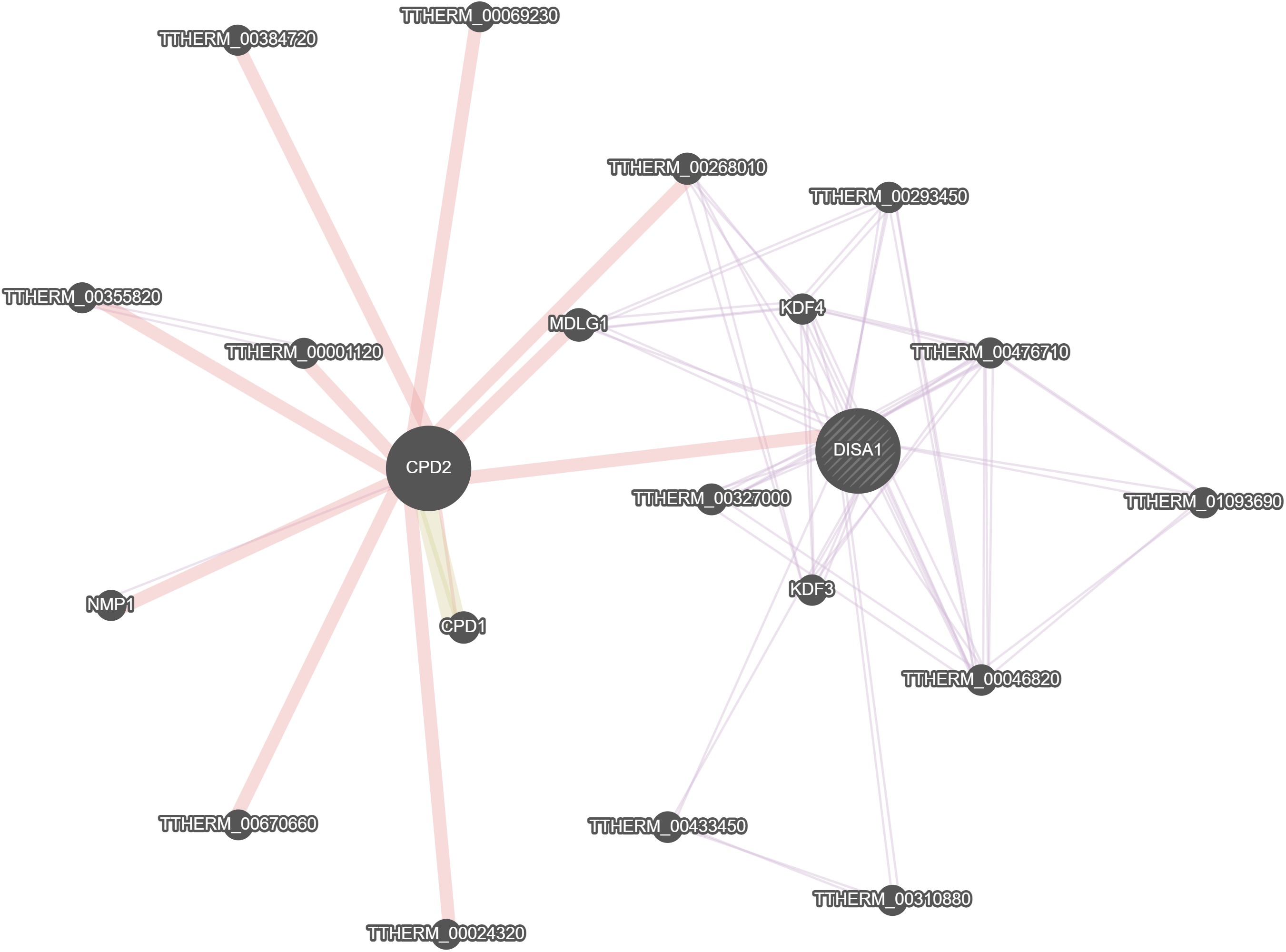
 GeneMania
GeneMania
 General Information
General Information
 Associated Literature
Associated Literature
 Sequences
Sequences
