Gene Model Identifier
TTHERM_01016030
Standard Name
MAC1
Aliases
PreTt02637 | 198.m00057 | 3746.m00321 | TTHERM_001016039
Description
MAC1 Appr-1-p processing enzyme family protein; Mono-ADP-ribosyltransferase ARTD/PARP
Genome
Browser (Macronucleus)
No Genome Browser Data Present
Genome Browser (Micronucleus)
No Genome Browser Data Present
>TTHERM_01016030(coding)
ATGAATAATATTTTTAGTAAAATATAAAAATTGCCAAAAATGATGAATTTATTTTAACTT
AAAAGTTATTTTAAAACTACCTAAAAACCTACTTATACTATTGGAAACTTATCTTCATAA
CCGATTTTGTAATAAAAGATTGGGGAAACTTAGATATCTATTGTTAAAAATGATCTAACA
ATGGAAAATGTTGATGCGATTGTAAACGCTGCTAATAACTTTTTAGCACATGGAGGAGGA
GTTGCAGGAGCAATTTGCAGAAAGGGAGGAAGAATTATACAAAATTAGAGTTATGACATA
ATAAAAATAAGAAATAGAATTGAAAATGGAGAATCAGTCACTACTGAAGCTGGACAACTT
CCTTGTAAAAAAGTTATTCATACAGTAGGACCTATTTGGGAAGATGGAGACAGTAATGAA
AAAGAAGAGCTAGCTAAATGTATGGAAACAATTTTAAGAGAGGCTAAATTTTATAAATTA
AAATCTATATCTATACCAGCCATATCTTCTGGTATATTTGGATTCCCTAAATATTTGTGC
GCCAAAATTTTGCTAGAAGAAACTTAAAAGCTATTGAAGTATGATTACTCTAATTAATTT
GAAGAAATAAGATTCTGCAACTTTGATAACGAAACAGTTTAGGTATTTGCTGAAGAGTTT
TAAAAGCAATTTTAGAATAAAGAACCCTAGTAGATTGAATAGCAAAGCAAAAAAAAAAAA
GAAAATAATTAAAATGAAGGCCTAAACGAAGATTTTTAGGAAGAACAGAAAGATAATTTG
AAAAACTTAGAGAAACCAAAAATCTAAGACCAAGATCTTTCGAATAATAAGGAAAAGCAA
GCTTAGAAATCATAGGAAGAAAATGAAATTAAGAAATAAGAAATAAAAGAATACAAAGAT
AAACATAGTGAAATTTAAAAGGAACAAAAAAATGAAAACCTTGAAAAATTATCAAAACAA
AAAGAGTGGATTATTAAAGATGCTAAAAATAATATCTCATAAAACCCTAGCTATGTTAAA
TAAAATGAAGGAGATCAAGCAATAGATGCTTAATCTTAGTAGTCCTCATAAGTAAAAGGC
CAATAGAATAAGGATAACGAAACAAAAGAATGCAAAGATAAACATAGTGAAATTTAAAAG
GAAGACTAAAATGAAAATCAAGAATAAAAAAATGAAAACCTTGAATAAGAAGAAAATGAG
TAGATTATTGGAGATGTTAAAAATAATAACTCATACAAGCATAGCCATGTTAAATAAAAT
GATGGAGATCAAGCAGTAGATGCTTAATCTTAGTAGTTCTCATAAATAAAAGACCAATCT
AATGAGGATTAAGAAACAAAAGAATGCAAAGATAAACATAGTGAAATTTAAAAGGAAGAC
AAAAATGAAAATCAAGAATAAAAAAATGAAAACCTTGAATAAGAAGAAAATGAGTAGATT
ATTGGAGATGTTAAAAATAATAACTCATACTAGCCTAGCTTTGTTAAATAAAATCAAGGA
GATCAAGCAATAGATCCTAAATCTTAGTAGTTCTCATAAAAAAAAGACCAATCTAATGAG
ATACTTGGTGAGTCCTAAATTAAAAAAGTGAAACTTTGA
>TTHERM_01016030(gene)
GCAGCTCTCATTTAATATTCTAATAGTTTATAAGTAAAGTAATAATAAAATATTGCATAA
AATATATGAATAATATTTTTAGTAAAATATAAAAATTGCCAAAAATGATGAATTTATTTT
AACTTAAAAGTTATTTTAAAACTACCTAAAAACCTACTTATACTATTGGAAACTTATCTT
CATAACCGATTTTGTAATAAAAGATTGGGGAAACTTAGATATCTATTGTTAAAAATGATC
TAACAATGGAAAATGTTGATGCGATTGTAAACGCTGCTAATAACTTTTTAGCACATGGAG
GAGGAGTTGCAGGAGCAATTTGCAGAAAGGGAGGAAGAATTATACAAAATTAGAGTTATG
ACATAATAAAAATAAGAAATAGAATTGAAAATGGAGAATCAGTCACTACTGAAGCTGGAC
AACTTCCTTGTAAAAAAGTTATTCATACAGTAGGACCTATTTGGGAAGATGGAGACAGTA
ATGAAAAAGAAGAGCTAGCTAAATGTATGGAAACAATTTTAAGAGAGGCTAAATTTTATA
AATTAAAATCTATATCTATACCAGCCATATCTTCTGGTATATTTGGATTCCCTAAATATT
TGTGCGCCAAAATTTTGCTAGAAGAAACTTAAAAGCTATTGAAGTATGATTACTCTAATT
AATTTGAAGAAATAAGATTCTGCAACTTTGATAACGAAACAGTTTAGGTATTTGCTGAAG
AGTTTTAAAAGCAATTTTAGAATAAAGAACCCTAGTAGATTGAATAGCAAAGCAAAAAAA
AAAAAGAAAATAATTAAAATGAAGGCCTAAACGAAGATTTTTAGGAAGAACAGAAAGATA
ATTTGAAAAACTTAGAGAAACCAAAAATCTAAGACCAAGATCTTTCGAATAATAAGGAAA
AGCAAGCTTAGAAATCATAGGAAGAAAATGAAATTAAGAAATAAGAAATAAAAGAATACA
AAGATAAACATAGTGAAATTTAAAAGGAACAAAAAAATGAAAACCTTGAAAAATTATCAA
AACAAAAAGAGTGGATTATTAAAGATGCTAAAAATAATATCTCATAAAACCCTAGCTATG
TTAAATAAAATGAAGGAGATCAAGCAATAGATGCTTAATCTTAGTAGTCCTCATAAGTAA
AAGGCCAATAGAATAAGGATAACGAAACAAAAGAATGCAAAGATAAACATAGTGAAATTT
AAAAGGAAGACTAAAATGAAAATCAAGAATAAAAAAATGAAAACCTTGAATAAGAAGAAA
ATGAGTAGATTATTGGAGATGTTAAAAATAATAACTCATACAAGCATAGCCATGTTAAAT
AAAATGATGGAGATCAAGCAGTAGATGCTTAATCTTAGTAGTTCTCATAAATAAAAGACC
AATCTAATGAGGATTAAGAAACAAAAGAATGCAAAGATAAACATAGTGAAATTTAAAAGG
AAGACAAAAATGAAAATCAAGAATAAAAAAATGAAAACCTTGAATAAGAAGAAAATGAGT
AGATTATTGGAGATGTTAAAAATAATAACTCATACTAGCCTAGCTTTGTTAAATAAAATC
AAGGAGATCAAGCAATAGATCCTAAATCTTAGTAGTTCTCATAAAAAAAAGACCAATCTA
ATGAGATACTTGGTGAGTCCTAAATTAAAAAAGTGAAACTTTGAAGAACCATGTCTAATA
AATTTAATTAAAATTGATTTTAAAATAAAATTATCTAATTATATTAGCTATATTAAAAAA
GTAAGTGAAATCATTATTTTATTTCAAATT
>TTHERM_01016030(protein)
MNNIFSKIQKLPKMMNLFQLKSYFKTTQKPTYTIGNLSSQPILQQKIGETQISIVKNDLT
MENVDAIVNAANNFLAHGGGVAGAICRKGGRIIQNQSYDIIKIRNRIENGESVTTEAGQL
PCKKVIHTVGPIWEDGDSNEKEELAKCMETILREAKFYKLKSISIPAISSGIFGFPKYLC
AKILLEETQKLLKYDYSNQFEEIRFCNFDNETVQVFAEEFQKQFQNKEPQQIEQQSKKKK
ENNQNEGLNEDFQEEQKDNLKNLEKPKIQDQDLSNNKEKQAQKSQEENEIKKQEIKEYKD
KHSEIQKEQKNENLEKLSKQKEWIIKDAKNNISQNPSYVKQNEGDQAIDAQSQQSSQVKG
QQNKDNETKECKDKHSEIQKEDQNENQEQKNENLEQEENEQIIGDVKNNNSYKHSHVKQN
DGDQAVDAQSQQFSQIKDQSNEDQETKECKDKHSEIQKEDKNENQEQKNENLEQEENEQI
IGDVKNNNSYQPSFVKQNQGDQAIDPKSQQFSQKKDQSNEILGESQIKKVKL


 Identifiers and Description
Identifiers and Description
 External Links
External Links
 Domains
Domains
 Gene Expression Profile
Gene Expression Profile
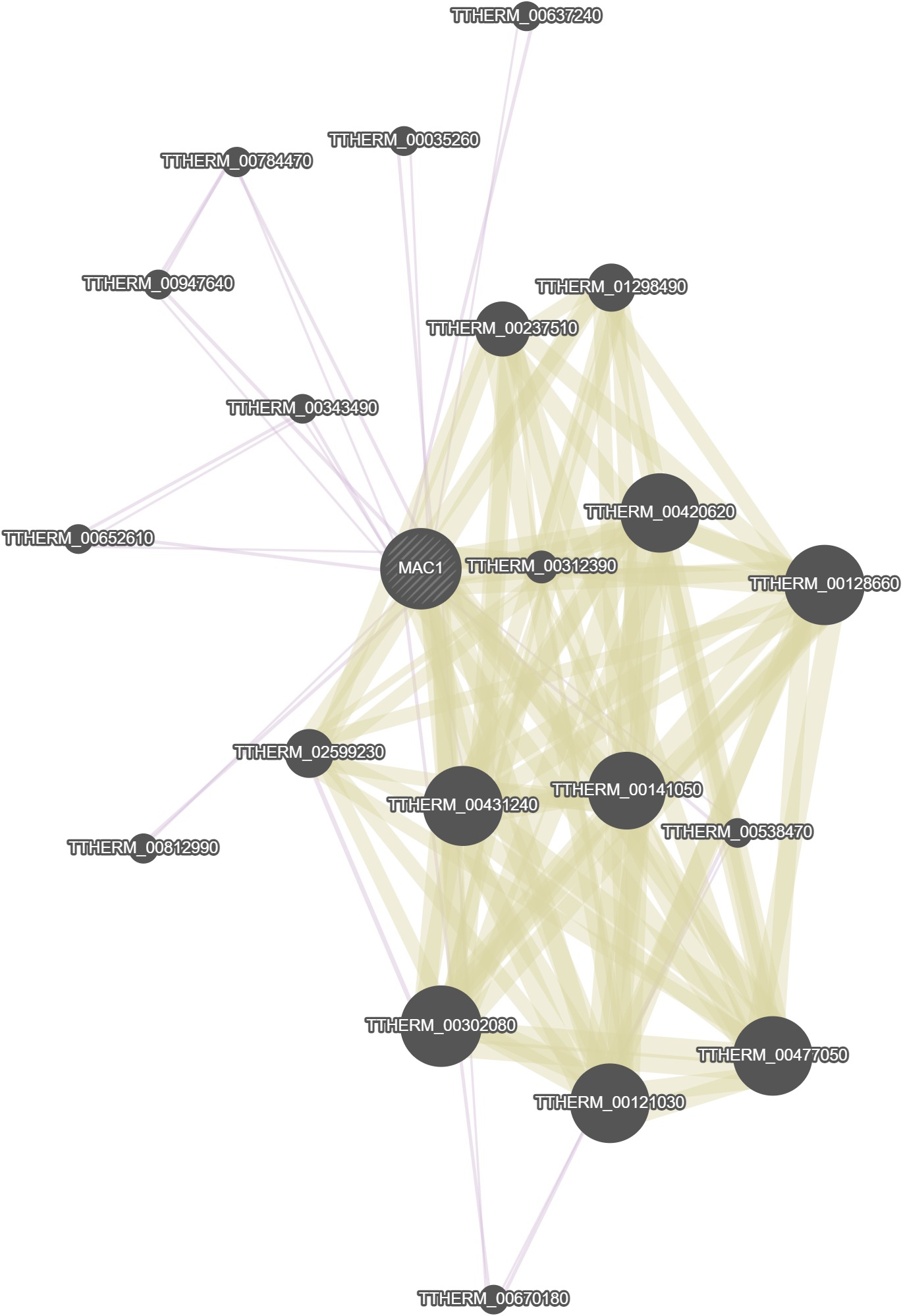
 GeneMania
GeneMania
 General Information
General Information
 Associated Literature
Associated Literature
 Sequences
Sequences
